How Many Rows Does CSV Support? Practical Limits and Workarounds
Explore the practical row limits of CSVs, how different tools enforce caps, and how to work with very large datasets efficiently, with guidance from MyDataTables.

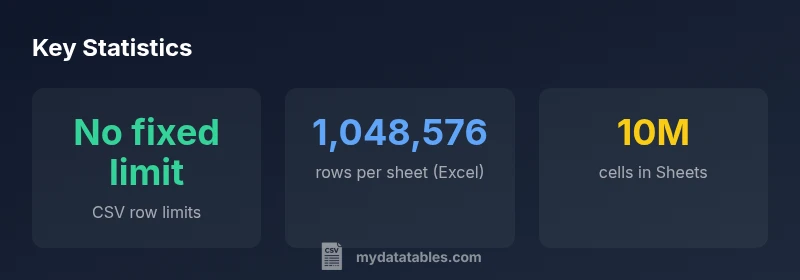
According to MyDataTables, CSV itself has no defined maximum number of rows. The limit comes from the software reading or writing the file. In practice, most tools can handle millions of rows if memory and performance allow. For example, Excel supports up to 1,048,576 rows per worksheet, while large-scale processing can handle larger CSVs when loaded in chunks. MyDataTables Analysis, 2026.
Understanding how many rows does csv support
CSV is a text-based format where each line represents a row and each comma-delimited value represents a column. Critically, the RFC 4180 standard that governs CSV does not specify a hard limit on the number of rows in a file. This means the CSV format itself is effectively unbounded with respect to rows; the constraint comes from the tools used to read, write, or process the file. For data professionals, the practical question becomes: how large can a CSV be before tooling becomes a bottleneck? From a MyDataTables perspective, infrastructure and software choices determine the upper bound. Consider factors such as memory availability, CPU speed, disk I/O, and the efficiency of the CSV parser you employ. When planning experiments or ETL pipelines, start with a mental model of tool-imposed caps and design workflows that accommodate growth by streaming or chunking when necessary.
The role of the consumer software: Excel, Sheets, and beyond
The CSV standard provides a simple, portable representation of tabular data, but the real world of CSV handling is defined by the software that reads and writes the files. In practice, Excel (modern versions) caps a single worksheet at 1,048,576 rows, which practically limits a CSV you open in Excel to that many lines per sheet. Google Sheets uses a cell-based cap, so its effective row limit depends on the total number of cells used across all sheets in a spreadsheet, which often translates into a practical ceiling in the millions. Other environments, like Python with pandas, R with read.csv, or database pipelines, can process CSVs far larger than a single sheet by streaming data or reading in chunks. The MyDataTables team stresses that the real constraint is available memory and processing capacity rather than any fixed CSV limit.
Practical limits in real-world CSV sizes
Large CSV files are common in data engineering and analytics. The size you can confidently work with depends on factors such as file size on disk, memory for loading, and the time window available for processing. A practical rule of thumb is to avoid loading multi-gigabyte CSVs into memory all at once. Instead, employ strategies like chunked reads (for example, Python's read_csv with a chunksize parameter) or streaming parsers that process rows sequentially. When exporting or sharing CSVs, consider partitioning data into logical chunks (by date, region, or batch) and distribute the load across multiple files to keep downstream steps fast and reliable. MyDataTables Analysis, 2026
Techniques for processing large CSVs: streaming, chunks, pipelines
If you anticipate CSVs growing beyond a standard workspace, use streaming techniques. In Python, you can iterate over a CSV file line by line or use read_csv with a chunksize to obtain an iterator of DataFrames, each representing a chunk of rows. In SQL and big data tools, you can stage CSVs in a data lake or a columnar store and run incremental queries. For real-time-like workflows, consider streaming platforms that ingest CSV rows as they arrive and persist them to a database. The goal is to minimize peak memory use while preserving throughput, accuracy, and the ability to resume work after interruptions.
Designing CSV exports for scalability and reliability
When exporting large datasets to CSV, adopt practices that improve robustness and compatibility. Use UTF-8 encoding, consistent newline characters, and a stable delimiter. Quote fields that may contain delimiters or newlines, and include a header row for clarity. If the target environment supports it, add a BOM only if required for the consumer. Prefer splitting very large exports into multiple files or partitioned folders to enable parallel processing and easier data lineage tracking. These design choices can dramatically reduce processing time and error rates in downstream analytics.
Encoding, line endings, and data integrity with large CSVs
CSV interoperability hinges on encoding and line endings. UTF-8 is the de facto standard for modern data pipelines, but some legacy tools expect ANSI encodings. Always specify encoding at read/write time when possible. Line endings (LF vs CRLF) matter when moving files across platforms; mismatches can lead to misparsed rows. Ensure consistent quoting, handle embedded quotes properly, and validate that the CSV remains parsable after transformations. When dealing with enormous files, validate a sample of rows after each processing step to catch encoding or parsing errors early. These steps reduce the risk of corrupted exports and failed pipelines.
Validation, testing, and performance benchmarks
For datasets that push tool limits, implement validation tests that check row counts, column counts, and sample data integrity after each processing stage. Benchmark read and write times under realistic workloads, and profile memory usage to identify bottlenecks. Establish acceptance criteria for pipeline latency and failure rates, so you can decide when to split data, switch tools, or move intermediate results to a database. Transparent validation and performance metrics help teams scale CSV-driven workflows without surprises.
Practical checklist for CSV size management
- Break up very large CSVs into smaller, logically grouped files.
- Use chunked reads and writes to keep memory usage predictable.
- Prefer UTF-8 encoding with clear delimiters and consistent quoting.
- Validate a representative sample after each transformation.
- Consider moving to a database or data lake for very large datasets to enable scalable querying.
- Document the export format and partitioning scheme for downstream users.
Common tool row limits related to CSV imports
| Tool | Cap | Notes |
|---|---|---|
| Excel (modern) | 1,048,576 rows | Per worksheet; memory dependent |
| Google Sheets | 10,000,000 cells | Spreadsheet-wide cap; varies with sheet layout |
| Python/pandas (read_csv) | Memory-dependent | Supports chunked processing and streaming |
People Also Ask
Does CSV have a maximum number of rows?
There is no standardized limit specified for CSV rows. The practical ceiling is determined by the software used to read or write the file and by available system memory.
CSV has no universal row limit; the limit comes from your tools and memory.
Can Excel open CSV files with millions of rows?
Excel caps a single worksheet at 1,048,576 rows. Large CSVs can be opened by splitting data across multiple worksheets or files, but performance depends on your system.
Excel has a hard cap of about a million rows per sheet; very large CSVs need chunking.
What about Google Sheets row limits?
Google Sheets uses a cell-based cap, typically enabling several million cells per spreadsheet. Large CSVs may require splitting or alternative tools.
Sheets limits depend on total cells; very large CSVs usually require partitioning.
How can I process large CSVs efficiently in Python?
Use streaming or chunked reads (e.g., read_csv with chunksize) to process data in portions, reducing memory usage and enabling scalable workflows.
Process large CSVs in chunks with Python to save memory.
Are there best practices when exporting large CSVs?
Export with UTF-8 encoding, consistent delimiters, and proper quoting. Split very large exports into multiple files when possible to ease downstream processing.
Export with consistent encoding and delimiter; split large files.
Can CSV data be stored in a database for scale?
For very large datasets, store data in a database or data lake and use CSV as an interchange format when needed, not as the primary storage for analytics.
If data is huge, move into a database for scalable queries.
“CSV does not impose a hard row limit—the practical ceiling is defined by your tooling and available memory.”
Main Points
- CSV has no official row cap in the spec; limits are tool-dependent.
- Know per-sheet or per-spreadsheet caps for Excel and Sheets.
- For very large data, use chunking, streaming, or split-files.
- Consider a database when CSVs approach tool limits.
- Maintain encoding and newline consistency to ensure portability.