CSV Perspective: A Clear Side-by-Side Strategy Guide
Explore a rigorous, data-driven comparison of two CSV-focused strategies: CSV-centric ingestion vs. relational-DB-first integration. Learn how governance, tooling, and analytics shape outcomes for data analysts, developers, and business users.

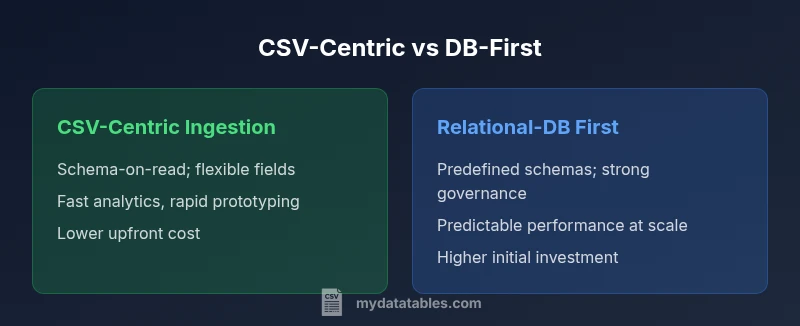
Two primary CSV-oriented strategies shape data pipelines: CSV-centric ingestion and DB-first integration. The CSV-centric approach prioritizes schema-on-read, flexible field handling, and rapid analytics with lightweight governance. The DB-first strategy emphasizes a predefined schema, strong data integrity, and centralized governance for enterprise-scale systems. Both aim to unlock CSV data, but the right choice depends on governance needs, analytics goals, and scale.
What is the CSV Perspective? Defining the comparison lens
Which of the following strategies represents a csv perspective? This question frames a long-standing debate about how to structure data pipelines when the primary data format is CSV. In this article, we compare two common trajectories: a CSV-centric ingestion approach and a relational-database-first workflow. Throughout, we maintain a disciplined lens on data quality, governance, and analytics goals. By the end, you’ll see how the choice influences data modeling, tooling, and scalability, and you’ll have a decision framework you can apply to real-world CSV projects.
This discussion is anchored in the practical reality that CSV files remain ubiquitous across teams. MyDataTables, for instance, observes that CSV files often serve as both source of truth and payload for exchange between systems. The goal is not to pick a single answer for every scenario but to identify which strategy better serves your current priorities while offering a clear path for future evolution.
Defining the Two Options and Why They Matter
Two principal strategies dominate csv-centric conversations: (1) CSV-centric ingestion with schema-on-read, progressive refinement, and analytics-first governance; and (2) a relational-database-first approach where a predefined schema and centralized data governance guide ingestion, transformation, and querying. The choice shapes how you model data, enforce quality, and scale analytics. In practice, teams often start with CSV files as entry points and evolve toward more structured databases as needs mature. The key is understanding where governance, speed, and flexibility matter most and how to preserve data provenance.
When you review these options, consider your organization’s data culture, the maturity of your data platform, and the expectations of downstream consumers. MyDataTables’s experience suggests that the CSV perspective can unlock rapid experimentation, while a DB-first approach provides rock-solid governance and long-term stability for enterprise workloads.
Comparison
| Feature | CSV-Centric Ingestion | Relational-DB First Integration |
|---|---|---|
| Data modeling approach | Schema-on-read; flexible fields; late binding | Predefined schema; strong normalization; upfront modeling |
| Data quality controls | At-ingestion validation with evolving schemas | Schema-enforced quality gates and master data rules |
| Scalability | Easier to scale horizontally via flat files and parallel processing | Predictable performance with indexed stores and optimized queries |
| Analytics performance | Rapid iteration for data science and ad-hoc analysis | Consistent, fast analytics on structured data with mature tooling |
| Tooling compatibility | Strong alignment with Python, R, and data science stacks | Wide ecosystem for SQL engines, BI tools, and data warehousing |
| Data lineage | Provenance tracked through ingestion steps; flexible lineage | Rigid lineage through stored schemas and ETL pipelines |
| Cost of ownership | Lower initial cost; incremental upgrades as needs grow | Higher upfront architecture cost; predictable long-term TCO |
| Best for | Fast analytics, data science, experimental pipelines | Governed environments, regulatory compliance, enterprise analytics |
Pros
- Faster onboarding for new CSV datasets, enabling rapid experimentation
- Greater flexibility in schema evolution without disruptive migrations
- Strong alignment with data science workflows and exploratory analytics
- Lower upfront tooling barriers for small teams
Weaknesses
- Potentially looser data governance and risk of schema drift
- Inconsistent data quality without centralized controls
- Higher long-term reliance on process discipline to maintain integrity
- Possible performance challenges as data volume grows without indexing
CSV-Centric Ingestion is typically the recommended starting point for teams prioritizing speed and flexibility.
Start with a CSV-centric approach to validate hypotheses and accelerate analytics. Consider a DB-first path later if governance, scale, and data integrity requirements intensify, or when regulatory demands demand strict control.
People Also Ask
Which option is best for starting a data-initialization project with CSVs?
For teams starting from CSVs, a CSV-centric ingestion approach often provides quicker wins and faster value realization. It supports rapid experimentation and helps you validate data customers’ needs before committing to a more rigid database schema.
If you’re just starting with CSV data, a CSV-centric approach typically offers faster wins and easier experimentation.
How do I maintain data quality in a CSV-centric workflow?
In a CSV-centric workflow, implement layered validation at ingestion, maintain a simple but evolving data dictionary, and establish automatic checks for drift. Document provenance and keep change logs so downstream teams understand how schemas may evolve.
Maintain data quality with in- ingestion checks, evolving dictionaries, and clear provenance.
Can I start with a hybrid approach and migrate to DB-first later?
Yes. A practical path is to start with CSV-centric processing for speed, then progressively introduce a DB-first layer for critical datasets that require strong governance, stable schemas, and auditability. Hybrid models are common in mature data ecosystems.
Hybrid approaches let you gain speed now and governance later as needed.
What tooling supports both strategies?
Many modern tools support both pathways, including data integration platforms, SQL engines, and scripting environments. Look for solutions that offer schema-on-read capabilities, strong metadata management, and lineage tracking to cover both strategies.
Choose tools with schema-on-read, metadata, and lineage support.
What is the CSV-perspective in practical terms?
The CSV-perspective focuses on CSV files as the primary data carriers, emphasizing flexible schemas, iterative analytics, and lightweight governance. It prioritizes speed and adaptability over upfront schema rigidity.
CSV-perspective centers on CSVs as the main data carriers with flexibility.
Main Points
- Prioritize the CSV perspective when speed and flexibility matter most
- Plan for governance as you scale data quality and lineage
- Hybrid approaches can blend flexibility with control
- Choose tooling that supports your intended data model and analytics workflows
- Define a migration path from CSV-centric to DB-first as needs evolve